WPF4.0用tablet实现手写输入(更新XP SP3下也能手写输入方法)
本文共 1803 字,大约阅读时间需要 6 分钟。
原文:
由于项目需求一个手写输入的控件,纠结了2天,终于搞定了。
主要是由于本人的英语不过关,一直和ocr混淆在一起,研究了Tesseract-OCR,我说奇怪了号称老牌OCR新版本还支持中文,怎么效果这么差,必须写个标准楷体才能够识别...||-_-.。还以为不行,必须得花钱买汉王的东西了.....一不小心让我知道了有tablet这种东西,大家可以体验一下,通过右键任务栏--工具栏--Tablet PC 输入面板。识别率相当高啊,于是谷歌了一下table SDK(google更懂E文)

05年的资源,各种下啊,迅雷、旋风、IE都没下下来。后来用谷歌阅览器自带的下载搞定....(果然很懂),满怀欣喜地打开看demo,效果不错啊,一看源码...我勒个去,全是C++的,不愧是6年前的资源。
废话不说了进入正题,微软手写识别无非是用InkAnalyzer这个类,具体用法,msdn....但是.net4.0 System.Windows.Ink;中这个类已经不存在了,只有3.5的有。我msdn了下,手写识别无非用到IACore.dll IALoader.dll IAWinFX.dll这3个动态库,于是上 zhaodll.com下了。引用后果然可以用,可是运行时报错,a百度了下,原来在4.0里用3.5的库要在app.config里加入下面这句配置
OK,完美运行了。效果如图:
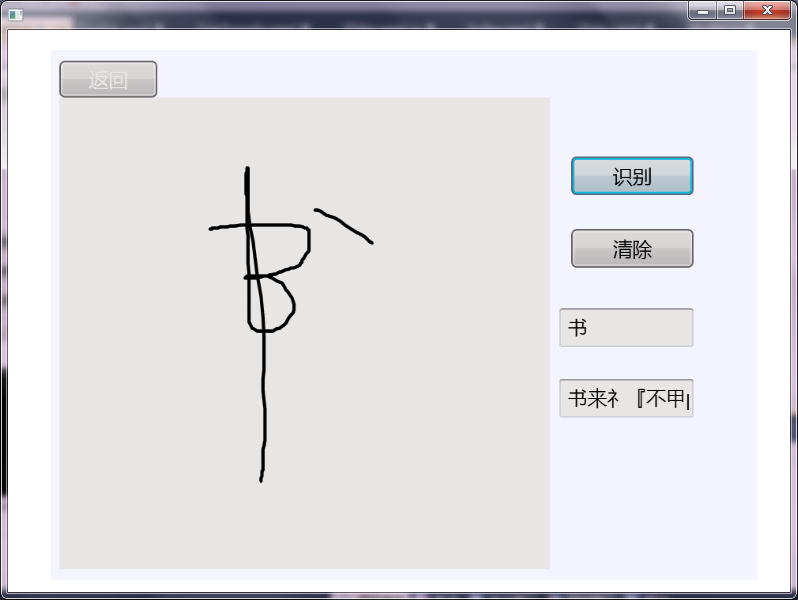
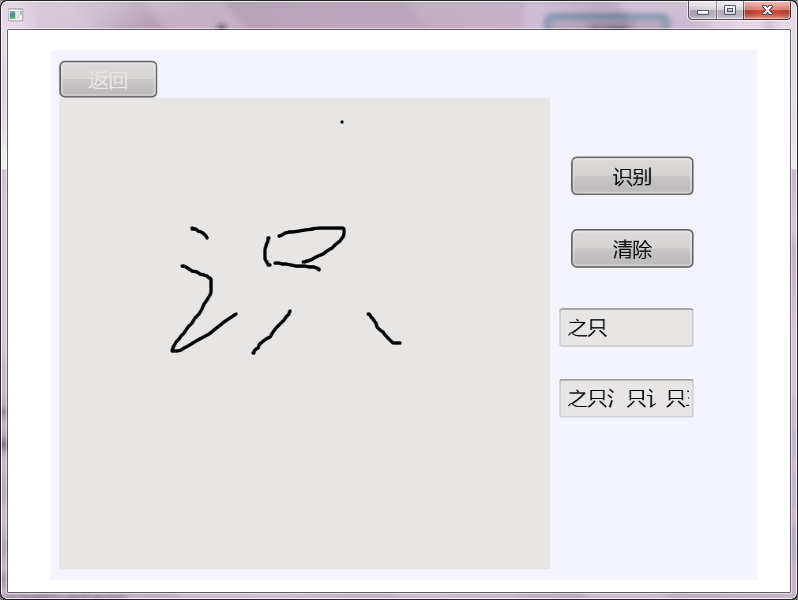
对我的草书的识别率相当不错啊,但是,默认会识别多个字符,导致“识”被拆分成两个字,跪求高手赐教,要怎么设置可以让它只识别一个字呢???
theInkAnalyer = new InkAnalyzer(); theInkAnalyer.AddStrokes(inkCanvs.Strokes); theInkAnalyer.SetStrokesLanguageId(inkCanvs.Strokes,0x0804); theInkAnalyer.SetStrokesType(inkCanvs.Strokes, StrokeType.Writing); AnalysisStatus status = theInkAnalyer.Analyze(); if (status.Successful) { textBox1.Text = theInkAnalyer.GetRecognizedString(); for (int i = 0; i < theInkAnalyer.GetAlternates().Count; i++) { textBox2.Text += theInkAnalyer.GetAlternates()[i].RecognizedString; } } else { MessageBox.Show("识别失败"); } 3个识别动态库
引用后就可以直接调用 InkAnalyzer 这个类了,具体用法自己msdn
更新
由于项目需求必须在XP SP3的操作系统上使用,会出现无法识别,上网找了点教程,貌似实现都很复杂,有的说重装了20次系统才搞定.....有点夸大其词了。
我找了某个比较新的教程,前后在虚拟机上尝试了4遍,总结了最简洁的方法:
inf里面的几个文件全部拷贝到windows的inf目录,tabletpc.rar里面的文件建议放到C:\i386,等下方便找。 1.运行1.reg,导入注册表后重启 2.运行3.cmd,弹出需要文件的窗口时,单击“浏览”,定位到tabletpc.rar的解压目录。安装过程中会出现无法识别XP版本问题,点“取消”,再点“是”。忽略掉。 3.完成后重启搞定,可以用官方测试软件试下看看搞定否。
我前后试了4次,尽管方法不同但是,没有一次是会导致系统蹦掉的。
用到的文件打包下载:

转载地址:http://htwuo.baihongyu.com/
你可能感兴趣的文章
HDOJ-1010 Tempter of the Bone
查看>>
日本开设无人机专业,打造无人机“人才市场”
查看>>
190行代码实现mvvm模式
查看>>
兼容几乎所有浏览器的透明背景效果
查看>>
Linux VNC server的安装及简单配置使用
查看>>
阿里宣布开源Weex ,亿级应用匠心打造跨平台移动开发工具
查看>>
Android项目——实现时间线程源码
查看>>
招商银行信用卡重要通知:消费提醒服务调整,300元以下消费不再逐笔发送短信...
查看>>
C#_delegate - 调用列表
查看>>
[转]Windows的批处理脚本
查看>>
多维数组元素的地址
查看>>
数据库运维体系_SZMSD
查看>>
js的AJAX请求有关知识总结
查看>>
三分 POJ 2420 A Star not a Tree?
查看>>
修改OBS为仅直播音频
查看>>
OCA读书笔记(3) - 使用DBCA创建Oracle数据库
查看>>
Python基础进阶之路(一)之运算符和输入输出
查看>>
阻塞非阻塞异步同步 io的关系
查看>>
ClickStat业务
查看>>
spring3.0.7中各个jar包的作用总结
查看>>